Consider the following question:
Which of the following two statements is logically true?
- All planets of the Solar System orbit the Sun. The Earth orbits the Sun. Consequently, the Earth is a planet of the Solar System.
- God is the creator of all things which exist. The Earth exists. Consequently, God created the Earth.
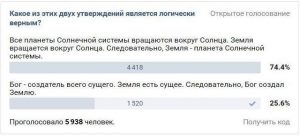 I've seen this question or variations of it pop up as "provocative" posts in social networks several times. At times they might invite lengthy discussions, where the participants would split into camps - some claim that the first statement is true, because Earth is indeed a planet of the Solar System and God did not create the Earth. Others would laugh at the stupidity of their opponents and argue that, obviously, only the second statement is correct, because it makes a valid logical implication, while the first one does not.
I've seen this question or variations of it pop up as "provocative" posts in social networks several times. At times they might invite lengthy discussions, where the participants would split into camps - some claim that the first statement is true, because Earth is indeed a planet of the Solar System and God did not create the Earth. Others would laugh at the stupidity of their opponents and argue that, obviously, only the second statement is correct, because it makes a valid logical implication, while the first one does not.
Not once, however, have I ever seen a proper formal explanation of what is happening here. And although it is fairly trivial (once you know it), I guess it is worth writing up. The root of the problem here is the difference between implication and provability - something I myself remember struggling a bit to understand when I first had to encounter these notions in a course on mathematical logic years ago.
Indeed, any textbook on propositional logic will tell you in one of the first chapters that you may write
![\[A \Rightarrow B\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-ea34633c938e03a2e8397d1b76fd0d76_l3.png "Rendered by QuickLaTeX.com")
to express the statement " implies
implies  ". A chapter or so later you will learn that there is also a possibility to write
". A chapter or so later you will learn that there is also a possibility to write
![\[A \vdash B\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-78bba64c09d2b0962343fcc9994e9bb9_l3.png "Rendered by QuickLaTeX.com")
to express a confusingly similar statement, that " is provable from ". To confirm your confusion, another chapter down the road you should discover, that  is the same as
is the same as  , which, in turn, is logically equivalent to
, which, in turn, is logically equivalent to  . Therefore, indeed, whenever is true, is true, and vice-versa. Is there a difference between
. Therefore, indeed, whenever is true, is true, and vice-versa. Is there a difference between  and
and  then, and why do we need the two different symbols at all? The "provocative" question above provides an opportunity to illustrate this.
then, and why do we need the two different symbols at all? The "provocative" question above provides an opportunity to illustrate this.
The spoken language is rather informal, and there can be several ways of formally interpreting the same statement. Both statements in the puzzle are given in the form ", , consequently  ". Here are at least four different ways to put them formally, which make the two statements true or false in different ways.
". Here are at least four different ways to put them formally, which make the two statements true or false in different ways.
The Pure Logic Interpretation
Anyone who has enough experience solving logic puzzles would know that both statements should be interpreted as abstract claims about provability (i.e. deducibility):
![\[A, B \vdash C.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-4eb60041baefa0b8718d44bdd9fa0b37_l3.png "Rendered by QuickLaTeX.com")
As mentioned above, this is equivalent to
![\[(A\,\&\, B) \Rightarrow C.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-5bccce433bd3a0724870f223f4fd3ced_l3.png "Rendered by QuickLaTeX.com")
or
![\[\vdash (A\,\&\, B) \Rightarrow C.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-402a5b95e072755957731b60556d336e_l3.png "Rendered by QuickLaTeX.com")
In this interpretation the first statement is wrong and the second is a correct implication.
The Pragmatic Interpretation
People who have less experience with math puzzles would often assume that they should not exclude their common sense knowledge from the task. The corresponding formal statement of the problem then becomes the following:
![\[[\text{common knowledge}] \vdash (A\,\&\, B) \Rightarrow C.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-4894dc7300b4b40aff1a16bfea854f87_l3.png "Rendered by QuickLaTeX.com")
In this case both statements become true. The first one is true simply because the consequent is true on its own, given common knowledge (the Earth is indeed a planet) - the antecedents and provability do not play any role at all. The second is true because it is a valid reasoning, independently of the common knowledge.
This type of interpretation is used in rhetorical phrases like "If this is true, I am a Dutchman".
The Overly Strict Interpretation
Some people may prefer to believe that a logical statement should only be deemed correct if every single part of it is true and logically valid. The two claims must then be interpreted as follows:
![\[([\text{common}] \vdash A)\,\&\, ([\text{common}] \vdash B)\,\&\, (A, B\vdash C).\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-8e649a393754d83b09b8ea37557c6957_l3.png "Rendered by QuickLaTeX.com")
Here the issue of provability is combined with the question about the truthfulness of the facts used. Both statements are false - the first fails on logic, and the second on facts (assuming that God creating the Earth is not part of common knowledge).
The Oversimplified Interpretation
Finally, people very unfamiliar with strict logic would sometimes tend to ignore the words "consequently", "therefore" or "then", interpreting them as a kind of an extended synonym for "and". In their minds the two statements could be regarded as follows:
![\[[\text{common}] \vdash A\,\&\, B\,\&\, C.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-057e5d2466a14971fb30f66ea7969d4f_l3.png "Rendered by QuickLaTeX.com")
From this perspective, the first statement becomes true and the second (again, assuming the aspects of creation are not commonly known) is false.
Although the author of the original question most probably did really assume the "pure logic" interpretation, as is customary for such puzzles, note how much leeway there can be when converting a seemingly simple phrase in English to a formal statement. In particular, observe that questions about provability, where you deliberately have to abstain from relying on common knowledge, may be different from questions about facts and implications, where common sense may (or must) be assumed and you can sometimes skip the whole "reasoning" part if you know the consequent is true anyway.
Here is an quiz question to check whether you understood what I meant to explain.
"The sky is blue, and therefore the Earth is round." True or false?

 and the bias term
and the bias term  . While the problem of finding
. While the problem of finding ")
![\[\alpha_t^0\left(\frac{1}{\gamma}\sum_{i=1}^\ell \alpha_i^0y_i(x_t * x_i) + b-1+\xi_i\right) = 0\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-307ccd09d2869e87f9bf8e43968fc587_l3.png "Rendered by QuickLaTeX.com")
 term, which is unknown, hence the equation is not useful for finding
term, which is unknown, hence the equation is not useful for finding ")
")
 , such that
, such that  , i.e. there must exist at least one training point lying exactly on the margin. Although in most practical situations such support vectors will indeed exist, it is also theoretically possible that there won't be any, i.e. not a single support vector will lie exactly on the margin. Thus, for purposes of implementing SVMs, the provided specification is incomplete.
, i.e. there must exist at least one training point lying exactly on the margin. Although in most practical situations such support vectors will indeed exist, it is also theoretically possible that there won't be any, i.e. not a single support vector will lie exactly on the margin. Thus, for purposes of implementing SVMs, the provided specification is incomplete.
 such that the corresponding
such that the corresponding  are strictly between 0 and
are strictly between 0 and  .
.

![\[P[T=125|A=a]=\frac{1}{\sqrt{2\pi 10^2}}\exp\left(-\frac{1}{2}\frac{(125-a)^2}{10^2}\right)\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-71cbad335e7c1df695c1e3fddcb59519_l3.png "Rendered by QuickLaTeX.com")
![P[T=125|A=a]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-d636bf3ce38ceb5b2ca24cb3e5722fd0_l3.png "Rendered by QuickLaTeX.com") , you maximize the a-posteriori probability
, you maximize the a-posteriori probability ![P[A=a|T=125]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-0fb0b91482de103b2722200ed4c1ffbb_l3.png "Rendered by QuickLaTeX.com") . The corresponding expression is:
. The corresponding expression is:
![\begin{multiline} P[A=a|T=125] \sim P[T=125|A=a]\cdot P[A=a] = \\ = \frac{1}{\sqrt{2\pi 10^2}}\exp\left(-\frac{1}{2}\frac{(125-a)^2}{10^2}\right)\cdot \frac{1}{\sqrt{2\pi 15^2}}\exp\left(-\frac{1}{2}\frac{(110-a)^2}{15^2}\right) \end{multiline}](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-783dc171af3ba91deedff337cb18da0b_l3.png "Rendered by QuickLaTeX.com")
![\[E[a|T=125] = \int a \mathrm{dP}[a|T=125]\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-9ad6d3c21e08ac9a34351b754d264321_l3.png "Rendered by QuickLaTeX.com")






