Ever since Erwin Schrödinger described a thought experiment, in which a cat in a sealed box happened to be "both dead and alive at the same time", popular science writers have been relying on it heavily to convey the mysteries of quantum physics to the layman. Unfortunately, instead of providing any useful intuition, this example has instead laid solid base to a whole bunch of misconceptions. Having read or heard something about the strange cat, people would tend to jump to profound conclusions, such as "according to quantum physics, cats can be both dead and alive at the same time" or "the notion of a conscious observer is important in quantum physics". All of these are wrong, as is the image of a cat, who is "both dead and alive at the same time". The corresponding Wikipedia page does not stress this fact well enough, hence I thought the Internet might benefit from a yet another explanatory post.
The Story of the Cat
The basic notion in quantum mechanics is a quantum system. Pretty much anything could be modeled as a quantum system, but the most common examples are elementary particles, such as electrons or photons. A quantum system is described by its state. For example, a photon has polarization, which could be vertical or horizontal. Another prominent example of a particle's state is its wave function, which represents its position in space.
There is nothing special about saying that things have state. For example, we may say that any cat has a "liveness state", because it can be either "dead" or "alive". In quantum mechanics we would denote these basic states using the bra-ket notation as  and
and  . The strange thing about quantum mechanical systems, though, is the fact that quantum states can be combined together to form superpositions. Not only could a photon have a purely vertical polarization
. The strange thing about quantum mechanical systems, though, is the fact that quantum states can be combined together to form superpositions. Not only could a photon have a purely vertical polarization  or a purely horizontal polarization
or a purely horizontal polarization  , but it could also be in a superposition of both vertical and horizontal states:
, but it could also be in a superposition of both vertical and horizontal states:
![\[\left|\updownarrow\right\rangle + \left|\leftrightarrow\right\rangle.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-bb28888160f3db2f261b765f75e441e0_l3.png "Rendered by QuickLaTeX.com")
This means that if you asked the question "is this photon polarized vertically?", you would get a positive answer with 50% probability - in another 50% of cases the measurement would report the photon as horizontally-polarized. This is not, however, the same kind of uncertainty that you get from flipping a coin. The photon is not either horizontally or vertically polarized. It is both at the same time.
Amazed by this property of quantum systems, Schrödinger attempted to construct an example, where a domestic cat could be considered to be in the state
![\[|\mathrm{dead}\rangle + |\mathrm{alive}\rangle,\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-9ecab632ef27f8b8005533935a7e456e_l3.png "Rendered by QuickLaTeX.com")
which means being both dead and alive at the same time. The example he came up with, in his own words (citing from Wikipedia), is the following:
A cat is penned up in a steel chamber, along with the following device (which must be secured against direct interference by the cat): in a Geiger counter, there is a tiny bit of radioactive substance, so small, that perhaps in the course of the hour one of the atoms decays, but also, with equal probability, perhaps none; if it happens, the counter tube discharges and through a relay releases a hammer that shatters a small flask of hydrocyanic acid. If one has left this entire system to itself for an hour, one would say that the cat still lives if meanwhile no atom has decayed. The first atomic decay would have poisoned it.
The idea is that after an hour of waiting, the radiactive substance must be in the state
![\[|\mathrm{decayed}\rangle + |\text{not decayed}\rangle,\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-bbee07fd5ed01692c8e6ba84b82ad9c2_l3.png "Rendered by QuickLaTeX.com")
the poison flask should thus be in the state
![\[|\mathrm{broken}\rangle + |\text{not broken}\rangle,\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-e315ad2954bd24886f4661f80a42485b_l3.png "Rendered by QuickLaTeX.com")
and the cat, consequently, should be
![\[|\mathrm{dead}\rangle + |\mathrm{alive}\rangle.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-c866e5bb696ac6396beffb961eb00bf0_l3.png "Rendered by QuickLaTeX.com")
Correct, right? No.
The Cat Ensemble
Superposition, which is being "in both states at once" is not the only type of uncertainty possible in quantum mechanics. There is also the "usual" kind of uncertainty, where a particle is in either of two states, we just do not exactly know which one. For example, if we measure the polarization of a photon, which was originally in the superposition  , there is a 50% chance the photon will end up in the state after the measurement, and a 50% chance the resulting state will be . If we do the measurement, but do not look at the outcome, we know that the resulting state of the photon must be either of the two options. It is not a superposition anymore. Instead, the corresponding situation is described by a statistical ensemble:
, there is a 50% chance the photon will end up in the state after the measurement, and a 50% chance the resulting state will be . If we do the measurement, but do not look at the outcome, we know that the resulting state of the photon must be either of the two options. It is not a superposition anymore. Instead, the corresponding situation is described by a statistical ensemble:
![\[\{\left|\updownarrow\right\rangle: 50\%, \quad\left|\leftrightarrow\right\rangle: 50\%\}.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-83c7effcd4325213c165a2ee48ff0f2d_l3.png "Rendered by QuickLaTeX.com")
Although it may seem that the difference between a superposition and a statistical ensemble is a matter of terminology, it is not. The two situations are truly different and can be distinguished experimentally. Essentially, every time a quantum system is measured (which happens, among other things, every time it interacts with a non-quantum system) all the quantum superpositions are "converted" to ensembles - concepts native to the non-quantum world. This process is sometimes referred to as decoherence.
Now recall the Schrödinger's cat. For the cat to die, a Geiger counter must register a decay event, triggering a killing procedure. The registration within the Geiger counter is effectively an act of measurement, which will, of course, "convert" the superposition state into a statistical ensemble, just like in the case of a photon which we just measured without looking at the outcome. Consequently, the poison flask will never be in a superposition of being "both broken and not". It will be either, just like any non-quantum object should. Similarly, the cat will also end up being either dead or alive - you just cannot know exactly which option it is before you peek into the box. Nothing special or quantum'y about this.
The Quantum Cat
"But what gives us the right to claim that the Geiger counter, the flask and the cat in the box are "non-quantum" objects?", an attentive reader might ask here. Could we imagine that everything, including the cat, is a quantum system, so that no actual measurement or decoherence would happen inside the box? Could the cat be "both dead and alive" then?
Indeed, we could try to model the cat as a quantum system with and being its basis states. In this case the cat indeed could end up in the state of being both dead and alive. However, this would not be its most exciting capability. Way more suprisingly, we could then kill and revive our cat at will, back and forth, by simply measuring its liveness state appropriately. It is easy to see how this model is unrepresentative of real cats in general, and the worry about them being able to be in superposition is just one of the many inconsistencies. The same goes for the flask and the Geiger counter, which, if considered to be quantum systems, get the magical abilities to "break" and "un-break", "measure" and "un-measure" particles at will. Those would certainly not be a real world flask nor a counter anymore.
The Cat Multiverse
There is one way to bring quantum superposition back into the picture, although it requires some rather abstract thinking. There is a theorem in quantum mechanics, which states that any statistical ensemble can be regarded as a partial view of a higher-dimensional superposition. Let us see what this means. Consider a (non-quantum) Schrödinger's cat. As it might be hopefully clear from the explanations above, the cat must be either dead or alive (not both), and we may formally represent this as a statistical ensemble:
![\[\{\left|\text{dead}\right\rangle: 50\%, \quad\left|\text{alive}\right\rangle: 50\%\}.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-4ecaa77a523ce2911f68c8bf4eeefcb1_l3.png "Rendered by QuickLaTeX.com")
It turns out that this ensemble is mathematically equivalent in all respects to a superposition state of a higher order:
![\[\left|\text{Universe A}, \text{dead}\right\rangle + \left|\text{Universe B}, \text{alive}\right\rangle,\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-29c695f7c07bd26c55d8664083cd69b3_l3.png "Rendered by QuickLaTeX.com")
where "Universe A" and "Universe B" are some abstract, unobservable "states of the world". The situation can be interpreted by imagining two parallel universes: one where the cat is dead and one where it is alive. These universes exist simultaneously in a superposition, and we are present in both of them at the same time, until we open the box. When we do, the universe superposition collapses to a single choice of the two options and we are presented with either a dead, or a live cat.
Yet, although the universes happen to be in a superposition here, existing both at the same time, the cat itself remains completely ordinary, being either totally dead or fully alive, depending on the chosen universe. The Schrödinger's cat is just a cat, after all.

 in the relaxed state, and if we stretch it, making it longer by
in the relaxed state, and if we stretch it, making it longer by  , the two ends of the spring exert a contracting force of
, the two ends of the spring exert a contracting force of  . Assume we hold the top of the spring at the vertical coordinate
. Assume we hold the top of the spring at the vertical coordinate  and have it balance out. The lower end will then position at the coordinate
and have it balance out. The lower end will then position at the coordinate  , where the gravity force
, where the gravity force  is balanced out exactly by the spring force.
is balanced out exactly by the spring force.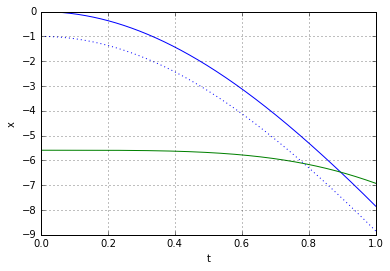
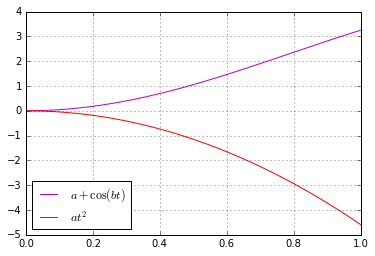
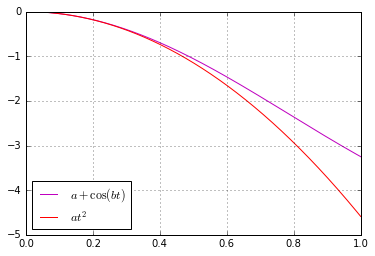
 . Recall the corresponding Taylor expansion:
. Recall the corresponding Taylor expansion:![\[\cos(x) = 1 - \frac{x^2}{2} + \frac{x^4}{24} + \dots \approx 1 - \frac{x^2}{2}.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-3414db091e89e7a357cc8138d6246d9a_l3.png "Rendered by QuickLaTeX.com")
 denote the coordinate of a point on a "relaxed" slinky. For example, in the two discrete models above the slinky had 4 and 10 points, numbered
denote the coordinate of a point on a "relaxed" slinky. For example, in the two discrete models above the slinky had 4 and 10 points, numbered  and
and  respectively. The continuous slinky will have infinitely many points numbered
respectively. The continuous slinky will have infinitely many points numbered ![[0,1]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-25b6d943ab489c05a3dbd5ea29087a48_l3.png "Rendered by QuickLaTeX.com") .
. denote the vertical coordinate of a point
denote the vertical coordinate of a point  . The acceleration of point
. The acceleration of point  , and there are two components affecting it: the gravitational pull
, and there are two components affecting it: the gravitational pull  and the force of the spring.
and the force of the spring. . As each point is affected by the stretch from above and below, we have to consider a difference of the "top" and "bottom" stretches, which is thus
. As each point is affected by the stretch from above and below, we have to consider a difference of the "top" and "bottom" stretches, which is thus  . Consequently, the dynamics of the slinky can be described by the equation:
. Consequently, the dynamics of the slinky can be described by the equation:![\[\frac{\partial^2 h(x,t)}{\partial^2 t} = a\frac{\partial^2 h(x,t)}{\partial^2 x} - g.\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-07981484366a38e2319cdf98ce1c32e7_l3.png "Rendered by QuickLaTeX.com")
 is some positive constant. Let us denote the second derivatives by
is some positive constant. Let us denote the second derivatives by  and
and  , replace
, replace  and rearrange to get:
and rearrange to get:![\[h_{tt} - v^2 h_{xx} = -g,\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-7d6dfe9bb994d93c9acd422979ca2a70_l3.png "Rendered by QuickLaTeX.com")
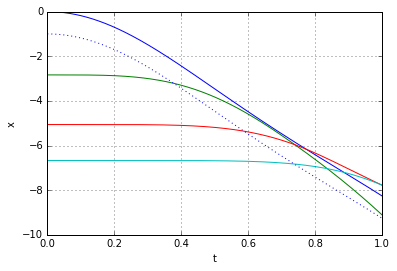
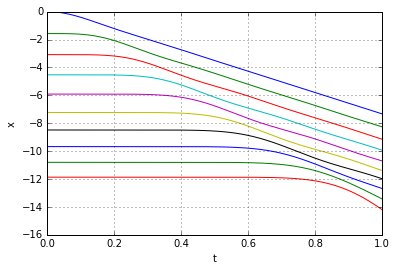
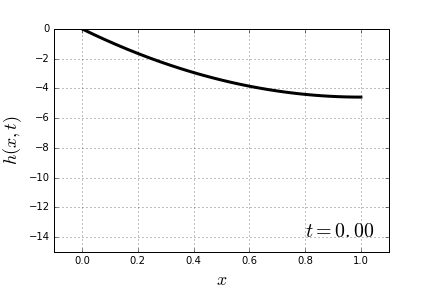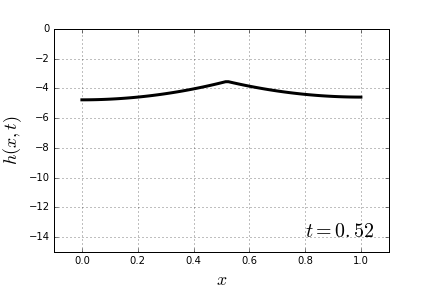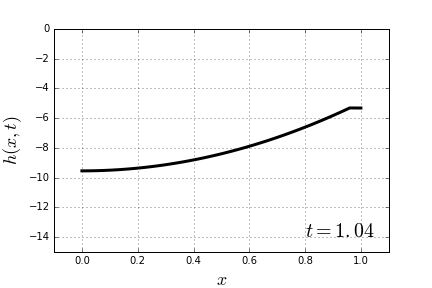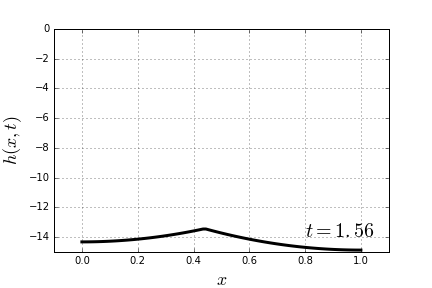
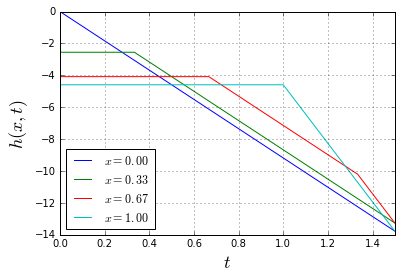
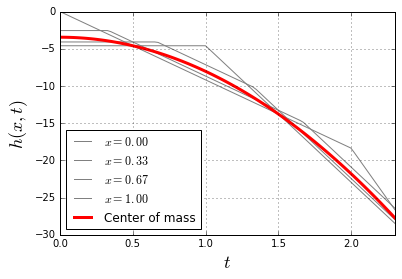
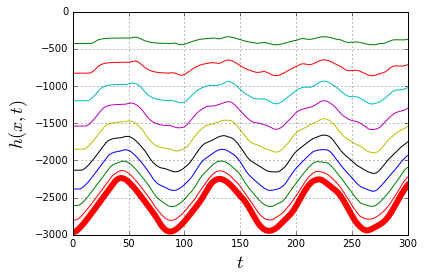
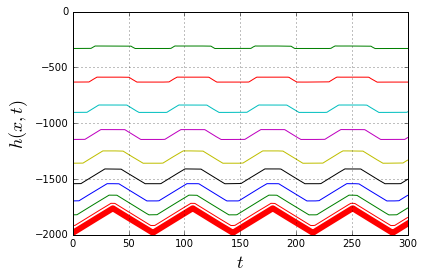
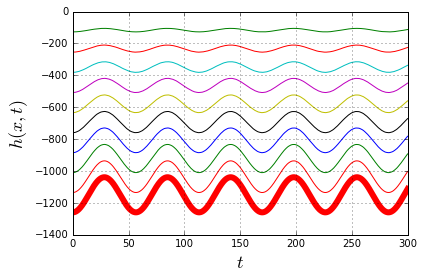
 through some medium. In our case the medium will be the slinky itself. Now it becomes apparent that, indeed, the lower end of the slinky should not move before the wave of disturbance, unleashed by releasing the top end, reaches it. Most of the explanations of the slinky drop seem to refer to that fact. However when it is stated alone, without the wave-equation-model context, it is at best a rather incomplete explanation.
through some medium. In our case the medium will be the slinky itself. Now it becomes apparent that, indeed, the lower end of the slinky should not move before the wave of disturbance, unleashed by releasing the top end, reaches it. Most of the explanations of the slinky drop seem to refer to that fact. However when it is stated alone, without the wave-equation-model context, it is at best a rather incomplete explanation. (because it is not moving at all),
(because it is not moving at all),  (because the top end is located at coordinate 0), and
(because the top end is located at coordinate 0), and  (because there is no stretch at the bottom). Combining this with (1) and searching for a polynomial solution, we get:
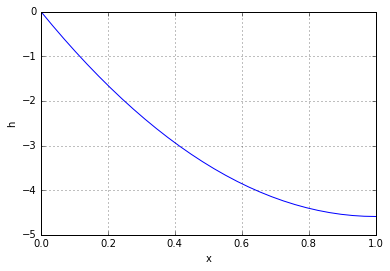
(because there is no stretch at the bottom). Combining this with (1) and searching for a polynomial solution, we get:![\[h(x, t) = h_0(x) = \frac{g}{2v^2}x(x-2).\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-ccb537e0ac9d6c0c9c1419a5e3779cea_l3.png "Rendered by QuickLaTeX.com")
 and
and  disappear and we may use the
disappear and we may use the ![\[h(x,t) = \frac{1}{2}(\phi(x-vt) + \phi(x+vt)) - \frac{gt^2}{2},\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-162c239646d7b38385bb3c3b22e162f9_l3.png "Rendered by QuickLaTeX.com")
![\[\text{ where }\phi(x) = h_0(\mathrm{mod}(x, 2)).\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-74110cd0e6bc77fb53f780a68a1fefca_l3.png "Rendered by QuickLaTeX.com")




![\[P[T=125|A=a]=\frac{1}{\sqrt{2\pi 10^2}}\exp\left(-\frac{1}{2}\frac{(125-a)^2}{10^2}\right)\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-71cbad335e7c1df695c1e3fddcb59519_l3.png "Rendered by QuickLaTeX.com")
![P[T=125|A=a]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-d636bf3ce38ceb5b2ca24cb3e5722fd0_l3.png "Rendered by QuickLaTeX.com") , you maximize the a-posteriori probability
, you maximize the a-posteriori probability ![P[A=a|T=125]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-0fb0b91482de103b2722200ed4c1ffbb_l3.png "Rendered by QuickLaTeX.com") . The corresponding expression is:
. The corresponding expression is:
![\begin{multiline} P[A=a|T=125] \sim P[T=125|A=a]\cdot P[A=a] = \\ = \frac{1}{\sqrt{2\pi 10^2}}\exp\left(-\frac{1}{2}\frac{(125-a)^2}{10^2}\right)\cdot \frac{1}{\sqrt{2\pi 15^2}}\exp\left(-\frac{1}{2}\frac{(110-a)^2}{15^2}\right) \end{multiline}](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-783dc171af3ba91deedff337cb18da0b_l3.png "Rendered by QuickLaTeX.com")
![\[E[a|T=125] = \int a \mathrm{dP}[a|T=125]\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-9ad6d3c21e08ac9a34351b754d264321_l3.png "Rendered by QuickLaTeX.com")






