"I need a publicly accessible webpage/wiki/web application/my revolutionary web-based startup. Where could I host it?"
I've been asked for advice on this topic many times by very different people, ranging from aspiring software engineers to their grandmothers. Apparently, finding a good answer to this question in Google is tricky - there are too many options to choose from, and way too many results lead to self-advertising of various hosting companies or overly biased opinions. Moreover, good advice on this topic changes every year, as new services become available. The following is my current answer to the question.

There are many possibilities for putting stuff out on the net, which differ in functionality, convenience and price. The answer to the question thus depends heavily on what actual need you want to solve. Here are the common needs along with possible solutions:
- I need to share some files/photos with my friends.
This is the most common case to start with, and in this case you do not need to "host a webpage" at all. Your first sharing option is, of course, your favourite social network: Facebook, Google+, VK, or wherever you already have an account anyway. If the social network option is unsuitable for some reason (say, your files are too large), consider one of the multitude of file sharing services, such as Dropbox, OneDrive, Google Drive, Yandex Disk, or whatnot. All of them are easy to use and free up to a certain space usage limit (within several gigabytes). If you need more space, consider getting a paid account. Alternatively, if you work at a company or study in a university, ask if your company/university has an internal OwnCloud installation. University of Tartu has one, for example. Finally, if you only need to share pieces of text or code, consider services like pastebin or Gist. - I need to set up a one-page site, a landing page, a wiki, a blog, or the like.
There are many great wiki systems, blogging, CMS or e-commerce solutions out there. They are reasonably easy to install and configure, if you have your own server, know the necessary system administration basics and have some hours to spare. In most situations, however, this would be an unnecessary waste of time. Numerous user-friendly services will let you set up a simple site without the need to bother with servers or any other technical details. Thus, if you need a wiki or a one-pager, try Google Sites or Wix, for example. If you are a developer and know your way around Git, consider Github Pages. If you need a typical personal blog, WordPress.com is a reasonable choice, although using your Facebook or Google+ account for blogging may often be even more reasonable. If you need a landing page with a visitor counter, Unbounce will help. If you want to sell stuff online, try E-bay. If all you need is a collaboratively editable document - why not use a simple Google Doc or a PiratePad? - I need to host a webapp.
If you need to publicly host a web application you created, you have three general choices: deploying it to an application container, using a virtual private server, or relying on a backend-as-a-service (BaaS) provider.
The popular application container providers are Heroku, Google AppEngine, Amazon Elastic Beanstalk, Azure App Service or IBM BlueMix. None of them are free, but all offer some amount of free credits or "free tier" functionality (Amazon and IBM's free tiers are probably the most generous overall). Hosting your application in an app container is simple as you do not need to deal with server configuration, scalability and security. However, it is not very flexible (you cannot always set up every single detail to your liking) nor is it the cheapest option.
If you know your way around server administration, getting a virtual private server could be much more comfortable. The popular providers to consider here are Amazon AWS (expensive, but very feature-rich and with a great free tier), Microsoft Azure (expensive, but you get a sign-up credit to try things out), DigitalOcean (affordable and popular, the referral link gives you $10 bonus on sign-up), ScaleWay (cheap) or ArubaCloud (very cheap, albeit with slightly worse server uptime guarantees). If you are a university student, check out whether your university could provide you the server space for free.
Many apps can be cleanly separated into a Javascript-based frontend and a simplistic backend, where the latter only needs to support a small number of standard operations such as verifying user identity or storing and retrieving data. In this case you could host your frontend pages on, say, Github Pages, and use a dedicated BaaS provider for the backend. Hundreds of those are available. If you need to start with something free and simple, I'd suggest you check out Google Firebase first. - Wait, what about the domain name?
Once you've published your site (no matter whether it is a google doc or a VPS) you may often want to make it accessible at a nice domain name. If you are not very fussy about the choice of the name, check out the freely available subdomain choices at FreeDNS. If you want to get something more fancy, you'll need to buy the name from a multitude of DNS registrar services out there (let me refer you to Namecheap, which is my current personal preference).

 , where
, where  is the "truly random" value from some probability space, and
is the "truly random" value from some probability space, and  is the "fixed but unknown" parameter. Your whole "school of thought" is now focused on clever
is the "fixed but unknown" parameter. Your whole "school of thought" is now focused on clever  ,
,  , or
, or  . As a result, the probability distribution he works with are not parameterized any more, and all of the clever techniques that the classical statisticians have invented over the centuries for estimating parameters become seemingly useless. At this point a classical statistician puts his hands down and goes home, as there is nothing to do for him - there are no "unknowns". The Bayesian is, however, left to struggle with mathematically trivial, yet computationally incredibly heavy methods for extracting essentially the same values that the classical statistician could have obtained using his "parameter estimation" approaches. That's why the Bayesian "school of thought" is mostly focused on computationally-efficient methods for
. As a result, the probability distribution he works with are not parameterized any more, and all of the clever techniques that the classical statisticians have invented over the centuries for estimating parameters become seemingly useless. At this point a classical statistician puts his hands down and goes home, as there is nothing to do for him - there are no "unknowns". The Bayesian is, however, left to struggle with mathematically trivial, yet computationally incredibly heavy methods for extracting essentially the same values that the classical statistician could have obtained using his "parameter estimation" approaches. That's why the Bayesian "school of thought" is mostly focused on computationally-efficient methods for  and apply the Bayes rule here and there, whenever it seems appropriate. A number of computations derived from the two theoretical backgrounds end up exactly the same.
and apply the Bayes rule here and there, whenever it seems appropriate. A number of computations derived from the two theoretical backgrounds end up exactly the same.



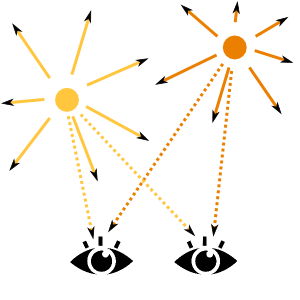




 and phase
and phase  and the wave from the second source reaches the pixel with amplitude
and the wave from the second source reaches the pixel with amplitude  and phase
and phase  . The two waves add up, so the pixel "feels" the overall oscillation of the form
. The two waves add up, so the pixel "feels" the overall oscillation of the form![\[a_1 \sin(ft + b_1) + a_2 \sin(ft + b_2).\]](https://fouryears.eu/wp-content/ql-cache/quicklatex.com-6291a8d39fb06066e62dd7a359aa13e6_l3.png "Rendered by QuickLaTeX.com")
 . Hence, to "record" the oscillation of each "pixel-buoy" we must store only two parameters: its intensity and phase.
. Hence, to "record" the oscillation of each "pixel-buoy" we must store only two parameters: its intensity and phase.